
一种新的矢量中文字库自动压缩方法
高宜琛,连宙辉,唐英敏,肖建国
一种新的矢量中文字库自动压缩方法
高宜琛,连宙辉,唐英敏,肖建国
(北京大学王选计算机研究所,北京 100080)
针对中文矢量字库体积较大,在嵌入式设备上使用不便的问题,提出了一种新的矢量中文字库自动压缩方法。基于部件拼接和复用的思想,首先使用一种传统图形学方法将字库中的字形拆分成不同部件,之后计算每个字形的部件复用关系,最后使用模拟退火算法迭代优化拼接字形,生成压缩字库。实验结果表明,该方法能够在维持原始字库风格和字形不变的条件下,生成体积仅为原始字库20%左右的压缩字库,从而提升了矢量中文字库在存储空间相对受限的嵌入式设备上的可用性。
矢量中文字库压缩;部件提取;部件复用;智能优化;模拟退火
随着移动信息化时代的到来,人们在嵌入式设备如智能手机、平板电脑上使用个性化中文字库的需求也与日俱增。与个人电脑不同,嵌入式设备虽然具有体积小巧、移动性好等特点,但存储空间也相对受限。庞大的汉字系统使得中文字库的体积通常是英文字库的几十甚至上百倍,导致其在嵌入式设备上的应用受到限制。为了解决这一问题,本文基于“部件复用”这一核心思想,提出了一种矢量中文字库的自动压缩方法,能够在保留原始字形和风格的条件下,生成体积只有原始字库20%左右的压缩字库,极大地提升了矢量中文字库在嵌入式设备上的可用性和易用性。
1 相关工作
矢量字库压缩,特别是矢量中文字库的压缩通常被建模成一个工程问题,因此学术界的研究和讨论也相对有限,一般有部件复用和曲线减点2种实现思路。FENG和JIN[1]提出使用仿射变换对中文字库进行压缩,该方法是基于部件复用的思想,压缩后的字库中仅保存一个基本部件库,在拼接字形时,通过计算一个部件库中部件到目标部件的仿射变换矩阵,并根据矩阵将部件库中的部件变换为目标部件,最后达到拼接成字的目的。虽然该方法可以直接操作字形外轮廓,但由于变换矩阵的计算需要在部件上选择特定的关键点,因此其在个性化字库上会出现选点不当的情况,从而导致压缩质量下降。TANG等[2]通过对部件使用基础的缩放平移实现了不错的拼字结果,同时还提出了一系列优化笔画粗细和对齐位置的方法,但该方法仅实现了对等线字体的压缩,因为对个性化字库而言,精准的笔画拆分很难实现。同时个性化字库的笔画也更加不规则,因此笔画级别的修正也很难得到实际应用。
当前大多数矢量字库都采用贝齐尔(Bezier)曲线和直线段来描绘字形轮廓,如:TrueType格式的矢量字库中的字形轮廓是采用二阶贝齐尔曲线和直线段来绘制的;OpenType格式的字库则引入了三次贝齐尔曲线来更精确地描绘字形轮廓。这些曲线和直线段均通过关键点来表达,若能实现对关键点数量的压缩,即能降低字库本身的体积。PAN等[3]提出了基于骨架指导的汉字字符图像矢量化算法,该方法采用动态曲线拟合的思想,相比于自动矢量化软件可以生成更加平滑和点数更少的矢量字形。XIA等[4]则将生成对抗网络模型[5]加入到了矢量化的流程之中,其使用生成对抗网络来简化字形图片,然后采用启发式的矢量化方法得到最终的矢量关键点。但是该方法的训练需要人工对部分图片进行标注和简化,这不仅带来了较大的工作量而且还需要标注者对矢量图形具有一定的理解,提高了标注的门槛,同时仅通过减点的方法无法显著压缩矢量中文字库的体积。
相比之下,本文提出的压缩方法不仅能够实现对任意矢量中文字库的压缩,而且无需变换矩阵或启发式的对齐方法,其借助模拟退火算法[6]来自动迭代优化压缩后字形,修复部件分割误差导致的拼接错误,使生成的压缩字库与原始字库更加接近。
2 本文方法
本文提出的矢量中文字库压缩方法的基本工作流程如图1所示,主要包括:部件拆分、部件复用关系计算和拼接字形迭代优化3个步骤。输入一款未经压缩的矢量中文字库后,系统首先对该字库中所有的字形进行部件级别的拆分,之后该系统需要维护一个部件库,并要求字库中的所有字形均必须能且仅能通过部件库中的部件拼接生成,因此这一步中系统需要不断将拆分好的部件加入到部件库中并计算字形与部件库之间的复用关系。最后针对由此生成的拼接字形,还提出了一种迭代优化的后处理方法,用于进一步调整字形中部件的位置和大小,得到质量更高的压缩字库,作为系统最终的输出结果。3个步骤中,第1步本文直接使用LIAN和XIAO[7]提出的基于图形学的笔划部件分割方法,这里不再赘述,而重点介绍其余2个步骤的内容。
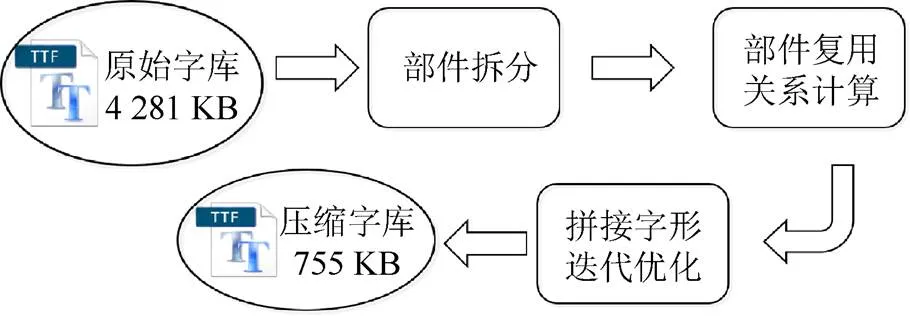
图1 矢量中文字库压缩系统工作流程图
2.1 部件复用关系计算
部件复用关系是指字形中的部件具体应该复用部件库中的哪个部件,是字库压缩系统中最核心的部分,其本质是计算字形部件与部件库中同类别部件的相似程度,然后选择部件库中最相似的部件来代替字形部件。当然,如果部件库中不存在该类别的部件或者所有部件均不符合复用要求,则将该字形部件加入到部件库中,并指定这一字形部件复用自己本身。
为了充分利用匹配对象的图像信息实现更加精准的匹配关系计算,本文提出了三特征匹配算法,用于更好地衡量2个部件的相似性。该算法顾名思义需要分别计算2个部件图像的3个特征,并以此为依据得出二者的差异度。其中第1个特征为缩放特征,即
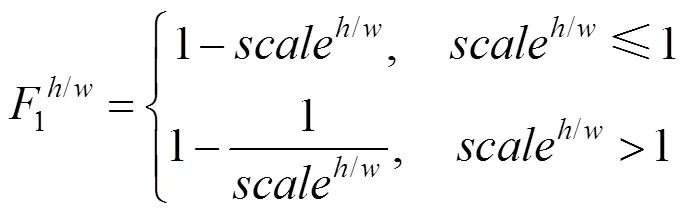
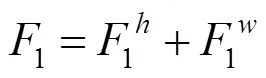
第2个特征为2张部件图像缩放到同一尺寸后前景像素的IoU距离,计算方法为2=1-,不再赘述。
第3个特征为图像的方向梯度直方图(histogram of oriented gradient,HOG)特征[8],即在一张图片中,局部目标的一些特征能够被边缘的方向密度分布所描述,因此该特征通过统计局部区域内图像的梯度方向直方图来生成图像特征。在表征字形时,由于字形一旦确定了边缘的轮廓,内部的区别一般不大,因此设置HOG特征是合理的。实际应用时,本文首先将部件库部件缩放至与字形部件相同的尺寸,然后分别计算其HOG特征向量,最后再计算2组向量曼哈顿距离的平均值,作为最终的HOG特征,记为3。
最后3个特征匹配差异度为
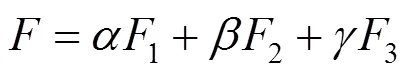
其中,,和均为权重,实验中分别取0.4,0.6和5.0。得到的差异度值将被用于评判2个部件是否构成复用关系,若小于用户设定的差异度阈值,则认为2个部件可以互相复用。此时,可以通过调整差异度阈值来控制压缩字库的精度,例如更小的阈值会对复用部件提出更高的相似度要求,进而提升压缩字库的质量,同时也增大了字库的部件数和体积。总而言之,通过修改阈值,用户可以方便地实现对压缩字库体积和质量之间的平衡。
2.2 拼接字形迭代优化
计算得到部件复用关系后,系统可生成一款完整的压缩字库,但其中部分字形会存在一些结构偏差,因此在该步中本文使用迭代优化的方式修复该偏差。
压缩字库中存储的信息包括2个部分,一部分是部件的轮廓信息,由二次贝齐尔曲线表示;另一部分则是字形的部件索引信息,包括字形复用的部件编号以及该部件在本字形中的位置和缩放比例。对前者的优化主要是修复分割错误的部件,但由于字形分割结果的自动修复难度很大,目前的方法很难实现完全自动的完美修复,因此后者自然成为了本文关注的优化对象。其中复用关系在2.1节中就已确定,而本节则针对部件位置和缩放比例的优化方法。该方法适用于图2中的情形,对一个目标字形而言,图2(a)是错误的分割结果,在生成图2(a)对应的压缩字形时,复用部件将按照分割结果的包围框进行放置,如图2(b)所示,即使使用了高质量的部件,拼接字形中依然存在一些错误。其目的是优化图2(b)中部件的位置和缩放比例,使字形达到图2(c)与目标字形图2(d)较为一致的效果。因此本文方法优化的对象其实是部件的位置和大小,相比于直接优化贝齐尔曲线,参数少了很多,同时由于目标字形的存在,本文使用智能优化算法对参数进行迭代式搜索。

图2 本文提出的拼接字形优化适用场景((a)目标字形的分割结果;(b)根据分割结果拼接成的字形;(c)优化可能达到的字形;(d)目标字形)
令为压缩字库中的一个字形,则={1,2,···,p},其中为字形中部件的数量,p为字形中每个部件的信息,且p={,offset,offset,scale,scale},其中为该部件在部件库中的索引;offset/y为该部件的左上角相对字形图像左上角在横/纵坐标上的偏移量;scale/y则为该部件在这个字形中相对其原始尺寸在水平/竖直方向上的缩放比例。渲染一个拼接字形的过程可以描述为:对中的每个部件p,首先在部件库中找到索引为的部件,然后将其水平和竖直方向分别缩放scale和scale倍,最后将其左上角移动到图像中(offset, offset)的位置即可。该方法优化的对象为字形中每个部件的offset/y和scale/y,因此对于一个包含有个部件的字形而言,该方法需要优化的参数个数为4。
由于无法直接根据2张字形图像计算出上述参数的最优解,因此本文使用了迭代优化的思想来渐进式地搜索各个参数。WONG和HSU[9]和PAK等[10]在其工作中使用了对中文字形各个部件的迭代优化,其首先将部件按照字形的结构信息拼接成字形,然后定义字形的美观度评价指标和不同的优化操作,如将左右结构的2个部件拉近或推远一定距离,这样美观度指标就可以作为迭代中的适值函数,判断当前字形是否符合要求,而优化操作则可以对当前字形的邻域进行采样,生成其他字形,推动迭代过程的进行。虽然与本文方法思想类似,但这2类方法都需要字形的结构信息作为指导,因此无法直接应用。另外PANG等[11]提出了通过优化网页元素属性的方式来实现对用户视线的引导,即使用梅特罗波利斯-黑斯廷斯算法[12-13](Metropolis– Hastings algorithm)对网页中元素的属性如按钮的大小、文本的颜色或图片间的距离等进行随机采样,然后通过设计好的适值函数来评判采样的优劣,并不断迭代后就能得到一个相对更好的网页设计。
本文借鉴了上述工作中的一些思想,通过对字形组成部件的位置和缩放比例的采样来迭代优化整个字形,同时由于目标字形的存在以及参数个数较少,因此本文最终使用相对简单的模拟退火算法作为整个优化的框架。
2.2.1 适值函数
与2.1节计算部件复用关系类似,这里的适值函数同样主要用于衡量2张字形图片的相似度,同时为了防止当前字形在优化过程中脱离本字符既定的结构,本文方法还在适值函数中加入了与标准字形结构相似度的计算,因此最终的适值函数由2部分组成,一部分为与目标字形图像级别的相似度F,另一部分为与标准字形结构级别的相似度F,最终的适值函数=F+wF,其中为权重,实验中取0.2。
与部件匹配类似,F包括了2张图像的宽高相似度,记为size,计算式同式(1),包括图像的前景和背景IoU,分别记为fore和back,计算过程不再赘述。此外受到SUN等[14]提出的字形美观度评价方法的启发,为了衡量字形轮廓之间的相似性,F还包括了2张图像凸包的IoU,记为hull。最终的图像级别的适值函数为
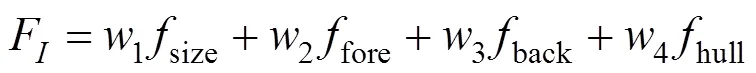
其中,w为权重,实验中依次为0.2,0.4,0.3和0.2。
直接使用当前字形与标准字形在图像级别上的相似度作为适值函数是不合理的,因为字体本身风格各异,内容差距大是正常现象,所以在文献[14]的启发下,本文设计了一系列表征字形结构的特征,并通过计算和比较标准字形和目标字形特征值之间的距离,来衡量二者结构上的相似性。具体地,结构特征包含以下3个方面:
(1) 部件相对字形中心的偏移。本文定义每个部件的位置为其外接包围框的中心,因此对每个部件都能计算出其相对字形中心的偏移量,之后再使用字形的宽高对偏移量的绝对值进行归一化,即可得到部件相对字形中心的位置特征。
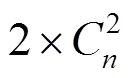

最后本文将上述求出的特征首尾相连组成一个维的特征向量,2个特征的相似度为
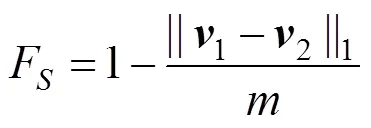
其中,1ÎR,2ÎR分别为标准字形和当前字形的结构特征向量。
2.2.2 优化器
本文使用模拟退火算法来优化当前字形,增加当前的适值函数值,直到迭代次数达到阈值或适值函数的变化小于某个精度。下面按照模拟退火算法中的要素来介绍本问题中使用的优化器:
(1) 初始状态。除了拼接生成的字形外,本文还加入了按照标准楷体的间架结构拼接生成的字形作为另一个的初始状态,并对多个初始状态独立优化,最终选择适值函数最大的字形。
(2) 新状态采样。通过对当前状态任意一个部件的偏移或缩放比例进行随机扰动来得到新字形,其中对偏移参数和缩放比例参数随机±1。
(3) 状态接受和状态拒绝。如果新状态导致适值函数下降且该下降在当前温度下没有被接受,那么按照模拟退火框架,该状态不应作为新的当前状态,而应重新进行采样。同时,如果参数本身不合法,如缩放比例不大于0或部件溢出边框,同样应该拒绝该状态。没有被拒绝的状态将会被接受为新的当前状态。
(4) 降温。内循环至一定次数后执行降温操作,降温后对接受状态的要求会更加苛刻,使整个搜索过程从广域搜索逐步转换为邻域搜索。
3 实验测试与结果分析
为了论证压缩方法的有效性,本文随机挑选了若干套风格各异的矢量中文字库,并对压缩前后的文件体积和字形结果进行了比较,结果如图3所示。其中“方正爆米花体”压缩前后体积分别为4 003 KB和987 KB,“方正哔哩君体”分别为3 519 KB和970 KB,“方正羽怒体”分别为9 174 KB和1 963 KB,“方正有猫在体”分别为5 660 KB和1 995 KB。

图3 经过压缩后的字形(子图第一行)与原始字形(子图第二行)的对比结果((a)方正爆米花体;(b)方正哔哩君体;(c)方正羽怒体;(d)方正有猫在体)
从图3可知,前3款字体的压缩字库在整体风格和结构上基本与原始字库保持一致,并且体积均只有原始字库的20%左右,实现了较好的字库压缩效果,但对最后一款“方正有猫在体”而言,其修饰纹理较多且与标准字形差距较大,因此部件分割方法通常会产生较大的分割误差,导致最终压缩字库的质量严重下降。
为了验证部件数与压缩率 (压缩字库体积与原始字库体积的比值) 的关系以及计算部件复用关系的方法有效性,本文对不同阈值下“方正羽怒体”的压缩结果进行了分析,并与仅考虑部件宽高的复用关系计算方法进行了对比,结果如图4所示。
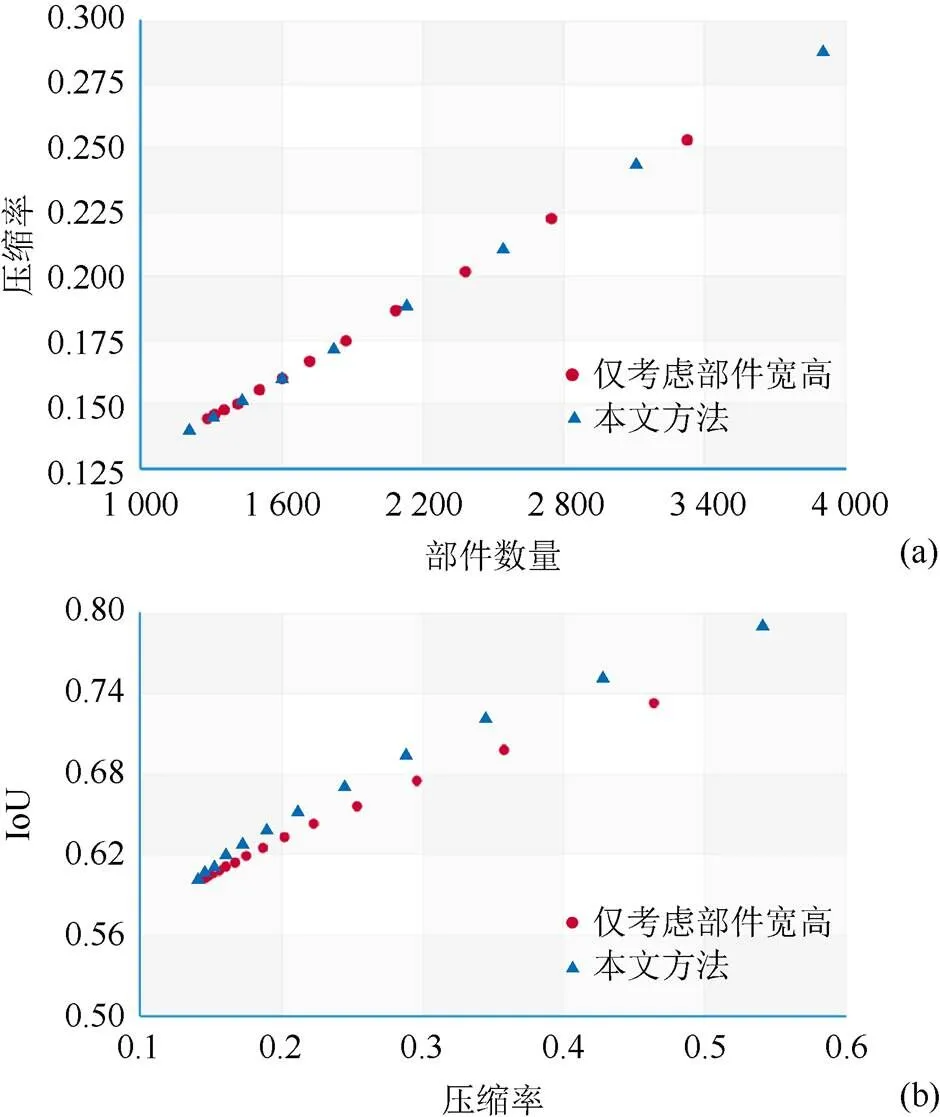
图4 不同阈值下本文方法与仅考虑部件宽高方法的对比((a)部件数量与压缩率的关系;(b)压缩率与字形IoU的关系)
从图4(a)中可以看出,部件数与压缩率基本呈线性正相关关系,更改部件匹配算法的阈值即可实现不同的压缩率,同时不同的匹配算法对本结果影响不大。接着本文将2款字库全部GB2312字符集[15]对应的6 763个字形图片之间的前景IoU的平均值定义为二者的相似度,并通过计算一款压缩字库与其原始字库间的相似度来量化压缩质量,本实验结果如图4(b)所示。可以看到,当压缩字库的体积增大时,其压缩质量也逐渐提升,说明压缩过程中丢失了更少的信息。此外,在压缩率相同的条件下,本文提出的方法能够获得更高的压缩质量,从而说明了其部件匹配方法能够让压缩字形与原始字形更加接近。
最后为了论证字形迭代优化方法的有效性,本文分别记录和分析了“方正爆米花体”、“方正羽怒体”和之前压缩质量不佳的“方正有猫在体”中300个字形的IoU变化和迭代优化过程。值得一提的是,实验时模拟退火算法的初始温度设置为1,终止温度为1e-9,降温系数为0.98,内循环次数为50次。
(1) 字形IoU。本文分别对3款字库优化前后的字形与目标字形进行了前景IoU的计算,由表1的结果可知,优化后每款字库中均有字形的IoU能够提升0.15左右,同时也有部分字形的IoU会下降,但从平均角度来看,优化后的3款字库在IoU指标上均比优化前要高,这也说明了本文方法的有效性。
(2) 迭代优化过程。如图5所示,图中第1列为优化前的字形,第2~5列为迭代过程中的部分中间状态,第6列为最终优化的结果,第7列为目标字形。可以看到迭代优化过程总体趋于使当前字形与目标字形更接近,但部分字形的迭代过程也无法避免地可能进入某些错误的状态,如何高效地对优化过程中的字形合法性进行限制也是提升本方法性能的关键点之一。

表1 3款字库字形优化前后IoU变化的极值和平均值

图5 迭代优化算法的可视化过程
4 结束语
本文采用了一种新的矢量中文字库自动压缩方法,基于部件拼接和复用的思想,该方法通过部件分割、复用关系计算和字形优化3个步骤,实现了在保留原始字形风格和结构的条件下,生成体积仅为原始字库20%左右的压缩字库的目的。实验结果也论证了本文方法的有效性和可行性,同时也展示了其在特定风格的字库上的局限性,采用更加精准的部件分割方法将是未来提升压缩字库质量的可行方向之一。
[1] FENG W R, JIN L W. Hierarchical Chinese character database based on radical reuse[J]. Journal of Computer Applications, 2006, 3.
[2] TANG Y M, ZHANG Y X, LU X Q. A truetype font compression method based on the structure of chinese characters[J]. Microelectronics & Computer, 2007, 24(6): 52-55.
[3] PAN W Q, LIAN Z H, TANG Y M, et al. Skeleton-guided vectorization of Chinese calligraphy images[C]//2014 IEEE 16th International Workshop on Multimedia Signal Processing (MMSP). New York: IEEE Press, 2014: 1-6.
[4] XIA Z Q, LIAN Z H, TANG Y M, et al. As-compact-as-possible vectorization for character images[M]//SIGGRAPH Asia 2018 Technical Briefs. New York: ACM Press, 2018: 1-4.
[5] GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets[C]//The 27th International Conference on Neural Information. New York: ACM Press, New York: ACM Press, 2014: 2672-2680.
[6] KIRKPATRICK S, GELATT C D, VECCHI M P. Optimization by simulated annealing[J]. Science, 1983, 220(4598): 671-680.
[7] LIAN Z H, XIAO J G. Automatic shape morphing for chinese characters[M]//SIGGRAPH Asia 2012 Technical Briefs. New York: ACM Press, 2012: 1-4.
[8] DALAL N, TRIGGS B. Histograms of oriented gradients for human detection[C]//2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05). New York: IEEE Press, 2005, 1: 886-893.
[9] WONG P Y C, HSU S C. Designing Chinese typeface using components[C]//The 19th Annual International Computer Software and Applications Conference (COMPSAC’95). New York: IEEE Press, 1995: 416-421.
[10] PAK K L, YEUNG D Y, PONG M C. Chinese glyph generation by heuristic search[EB/OL]. [2021-10-20]. http://citeseerx.ist. psu.edu/viewdoc/summary?doi=10.1.1.30.5026.
[11] PANG X, CAO Y, LAU R W H, et al. Directing user attention via visual flow on web designs[J]. ACM Transactions on Graphics (TOG), 2016, 35(6): 1-11.
[12] METROPOLIS N, ROSENBLUTH A W, ROSENBLUTH M N, et al. Equation of state calculations by fast computing machines[J]. The Journal of Chemical Physics, 1953, 21(6): 1087-1092.
[13] HASTINGS W K. Monte Carlo sampling methods using Markov chains and their applications[J]. Biometrika, 1970, 57(1): 97-109.
[14] SUN R J, LIAN Z H, TANG Y M, et al. Aesthetic visual quality evaluation of Chinese handwritings[C]//The 24th International Joint Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2015: 1867-1873.
[15] Wikipedia contributors. GB 2312[Z]. https://en.wikipedia.org/ w/index.php?title=GB_2312&oldid=887751871, 2019.
A new automatic compression method for Chinese vector fonts
GAO Yi-chen, LIAN Zhou-hui, TANG Ying-min, XIAO Jian-guo
(Wangxuan Institute of Computer Technology, Peking University, Beijing 100080, China)
To solve the inconvenient usage of large-size Chinese vector fonts in embedded devices, this paper proposes a new automatic font compression method. Based on the idea of reusing and assembling components, different parts were first extracted from the whole glyphs using a traditional computer graphics-based method and their reusing relationships were calculated. Then, they were assembled and their positions and scales were iteratively optimized using the simulated annealing algorithm to produce the final output. Experimental results demonstrate that the proposed method can generate a compressed font whose volume is only about 20% of the original font while maintaining the font style, thus improving the availability of Chinese vector fonts in embedded devices with limited storage spaces.
compression of Chinese vector fonts; components extraction; components reusing; intelligent optimization methods; simulated annealing algorithm
TP 391
10.11996/JG.j.2095-302X.2021030426
A
2095-302X(2021)03-0426-06
2020-12-23;
2021-01-12
23 December,2020;
12 January,2021
北京市科技新星计划项目(Z191100001119077);国家自然科学基金面上资助项目(61672056)
Beijing Nova Program of Science and Technology (Z191100001119077); National Natural Science Foundation of China (61672056)
高宜琛(1995-),男,内蒙古乌兰察布人,硕士研究生。主要研究方向为中文字库自动生成与压缩。E-mail:gaoyichen@pku.edu.cn
GAO Yi-chen (1995-), male, master student. His main research interests cover automatic generation and compression of Chinese vector fonts. E-mail:gaoyichen@pku.edu.cn
连宙辉(1985–),男,福建福州人,副教授,博士。主要研究方向为计算机图形学、计算机视觉等。E-mail:lianzhouhui@pku.edu.cn
LIAN Zhou-hui (1985-), male, associate professor, Ph.D. His main research interests include computer graphics and computer vision, etc. E-mail:lianzhouhui@pku.edu.cn