
��ͷ�㾦��������Ԩ
��ͷ���飺�ǻ��� �й���������ѧ���о������Ρ�������Ƭ���ܱ༭��2009“���������������������֮һ“���ۿ���������
������Ƭ����ӡ�����ӱR
������Ƭ��С��Ҷ����������岥����
һ�ֻ������ѧϰ�Ĺ�����ʶ��
���㽭��ѧѧ������ѧ�� 2019��3�� ���ߣ������ۣ���С�����������ƣ�������
��1.���ϴ�ѧ���������Ϣ��ѧѧԺ������ 400715��2.���ݹ���Ӧ�ü���ѧԺ�����о�Ժ�����ݱϽ�551700��
0 �� ��
��������Ϊһ����Ҫ�������������֣������8 000������ʷ������ǡ������������������š�������5�����ֲ��У����������������֮һ���������������������������һ��屦����ӵ�зdz��ƾõ���ʷ����������ġ������ĵ��ಢ�У����������������֮һ����������������һ����Ҫ��Դ������2009���ǻ��������ڸ����֡�����������������ֱȽ��о����⡷������ѧ���۵㣬�ǻ��������й���������ѧ���о������Ρ�������Ƭ���ܱ༭������һֱ������������ʷ���������������ĵ伮����Щ�ù�������д�ĵ伮������Ҫ����ʷ���������ֵ[1-2]������Ϊ���Ĺż������壺ʯ�̡��»���ľ빺�ֽ���������Զ������ģ�����壬���ȱ��ȫ����������ĵ�ʶ������˼������ս��

ͼ1 �������ҷֱ�Ϊ��д��ʯ�̡�ľ������Ƥ�ϵĹ�����Fig.1 From left to right are ancient Yi written on carved stone��wooden calf and sheepskin
��ǰ������������ʶ���о�����Ҫ�ǹ����������У���о������ɹ���Խ��١����������ѧ����÷��[3]��ʹ��ͼ��ָ����������ʶ��������Ԥ���������ж������ַ�����ϸ������һ������ֵ���ȴ�����֮��ʹ��ģ��ƥ�䷨��������ʶ����������[4]ʹ�������������ķ�����������ʶ��ʹ�õ������У����������������ʻ��ܶ�������ͶӰ�������ڷ�������У�ʹ�ö��������ͶƱ�ķ�ʽ��ȷ�����յ�������ջ���˽ӽ�96%��ʶ���ʣ��ǵ��͵�������ȡ��ӷ���ķ�������������[5]��ӡˢ��淶����ʶ���У�������ȡ�ܱ߷����ȵ���������������ѹ��Ϊ128ά��֮��ʹ�û��ڵ�һ���������������ֵ�ƥ���㷨����ʶ�������ڰ���10���������ֵIJ��Լ���һ��ʶ���ʴﵽ99.21%��������ʶ���о��У�ֵ��һ�����,2017��3�����������ѧɳ����������������������ķ���ֹ�ͬ���Ƴ���������д��ʶ���������������������ʶ�������������ƶ����������ֺ��Ļ��ı����ͷ�չ��
�������������ʶ�𣬹����ĵ���д�����Խϴ���ͳһ�淶����ʶ������Ҳ��֮���ӡ���Ȼ,���е���Ӣ��ʶ��������˽ϴ�ķ�չ����������ʷ������չ�IJ�ƽ�⣬��ǰ�Թ�����ʶ���о����١����ִ�Ĺ����Ļ�����Ϊ��д�壬��д��Ķ��������ɼӴ���ʶ����Ѷ�[3,6-7]����ˣ�������ʶ����һ��������ս�Ե�ģʽʶ�����⣬����Ҫ�����ڣ�
��1��ȱ���������д�����⡣��д�������ǹ�����ʶ��ɹ��Ĺؼ����أ�ֱ�Ӿ���ʶ���Ч������ǰ�Թ����ĵ��о���Ҫ�����ڶԹ��������������ϣ�������ר�ž�����ʶ������о����Ҳ������õĹ�������д�����⡣
��2���ַ����Ӵ�����ӵ���Ӵ���ַ�����2004�����ġ��ᴨǭ�������ּ����Ͱ���87 000�����[8]��������Ӵ���ַ������з�����һ��ʮ�ּ������
��3���������������α仯�϶࣬����ͳһ������ͬ������д����ͬ��������ʽ�仯�϶࣬������ʶ���Ѷȡ�
���IJ������ѧϰ�еľ���������Թ������ַ�����ʶ����4������������������չ��5��ģ�ͣ�Ȼ������Alpha-Betaɢ����Ϊ�ͷ����5��ģ�͵������Ԫ���½����Ա��룬������2��ȫ���Ӳ��������ѹ���������softmax��Թ������ַ������������֣��õ�����ʷֲ���ѡ������������Ϊʶ����ַ���
1 ����������Ļ�������ṹ
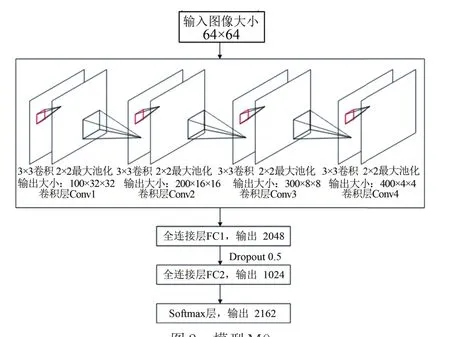
���Ĺ�����4��������������ڹ������ַ�ʶ��[9-11]����Ϊģ��M0����ͼ2��ʾ��M0��4�������㡢2��ȫ���Ӳ㡢1��softmax�㹹�ɡ�����Ż��������£�
Conv�������� (Convolutional layer)��
MP�����ػ��㣨Max Pooling layer����
Drop�����ʧ��㣨Dropout layer����
Softmax��Softmax�㣻
FC ��ȫ���Ӳ�(Fully Connected layer)��
���磬Conv(3×3,64,S2,P1)����ʾ��СΪ 3×3�����ͨ����Ϊ64������Ϊ2�����Ϊ1�ľ����㡣Ĭ�������Conv�IJ���Ϊ1�����Ϊ1����Ҫ��Ϊ��ʹ����ǰ������ͼ��С��ȡ���MP��Ĭ������´�СΪ2×2������Ϊ1�����Ϊ0����ʱ����ͼ��С��Ϊǰһ���1/4��
ģ��M0�����Ż�����Ϊ��
Input(64×64×1)-Conv(3×3,100)-MPConv(3×3,200)-MP-Conv(3×3,300)-MPConv(3×3,400)-MP-FC(2 048)-Drop(0.5)-FC(1 024)-Softmax(2 162)��
������ģ��M0Ϊ�������ֱ�������������ǰ����������һ��3×3�ľ����㣬�õ�4��ģ�ͣ�M1��M2��M3��M4������ģ�͵ķ��Ż��������1��ʾ��M1�ڵ�1��������ǰ������һ��ͨ����Ϊ50�ľ����㣻M2�ڵ�2��������ǰ������һ��ͨ����Ϊ150�ľ����㣻M3�ڵ�3��������ǰ������һ��ͨ����Ϊ250�ľ����㣻M4�ڵ�4��������ǰ������һ��ͨ����Ϊ350�ľ����㣻��M5��M1��M4���еIJ�����Ӧ�õ�ģ��M0�ϣ���ͬʱ�����о������ǰ������һ��3×3�ľ����㣬�õ�ģ��M5����ͼ2��ʾ��
ͼ2 ģ��M0Fig.2 Model M0
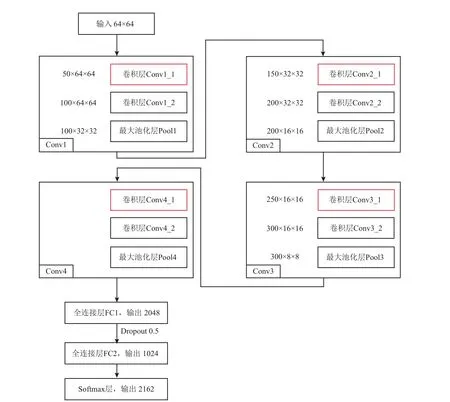
ģ��M5�ṹ��ͼ3��ʾ��������4��������㡢2��ȫ���Ӳ㡢1��softmax�㹹�ɣ���ʹ��ReLU�����Գ�softmax����������������м������ÿ�����������2��������3×3�������Լ�1��2×2���ػ��㹹�ɣ������˵����ͨ������50Ϊ�������е�����Ϊ�˽�һ���淶ģ����������M5ģ�Ͱ�����4�����������������ʽ��������
���1ģ������
Conv1��Conv1_1�������� 4 k����Conv1_2��������405 k����Pool1
ͼ3 ģ��M5Fig.3 Model M5
ͨ������50��100��100
����ߴ磺32×32
������100
���ڵ�1��������Conv1�����ɾ�����Conv1_1��Conv1_2���ػ��� Pool1���ɣ�ͨ�����ֱ�Ϊ50��100��100���ò�����Ϊ100�Ŵ�СΪ32×32������ͼ��������Conv1_1��Conv1_2�IJ������ֱ�Ϊ4 k��405 k������������Conv1�IJ�����Ϊ409 k��
���2ģ������
Conv2��Conv2_1�������� 1 215 k����Conv2_2�������� 2 430 k����Pool2
ͨ������150��200��200
����ߴ磺16×16
������200
���3ģ������
Conv3��Conv3_1�������� 4 050 k����Conv3_2�������� 6 075 k����Pool3
ͨ������250��300��300
����ߴ磺8×8
������300
���4ģ������
Conv4��Conv4_1�������� 8 505 k����Conv4_2�������� 11 340 k����Pool4
ͨ������350��400��400
����ߴ磺4×4
������400
����ȫ���Ӳ���softmax�㣬������ֱ�Ϊ13 107��2 097��2 214 k�����е�1��ȫ���Ӳ�����ʧ�����Ϊ0.5��ȫ����IJ�������Լ51 442 k��
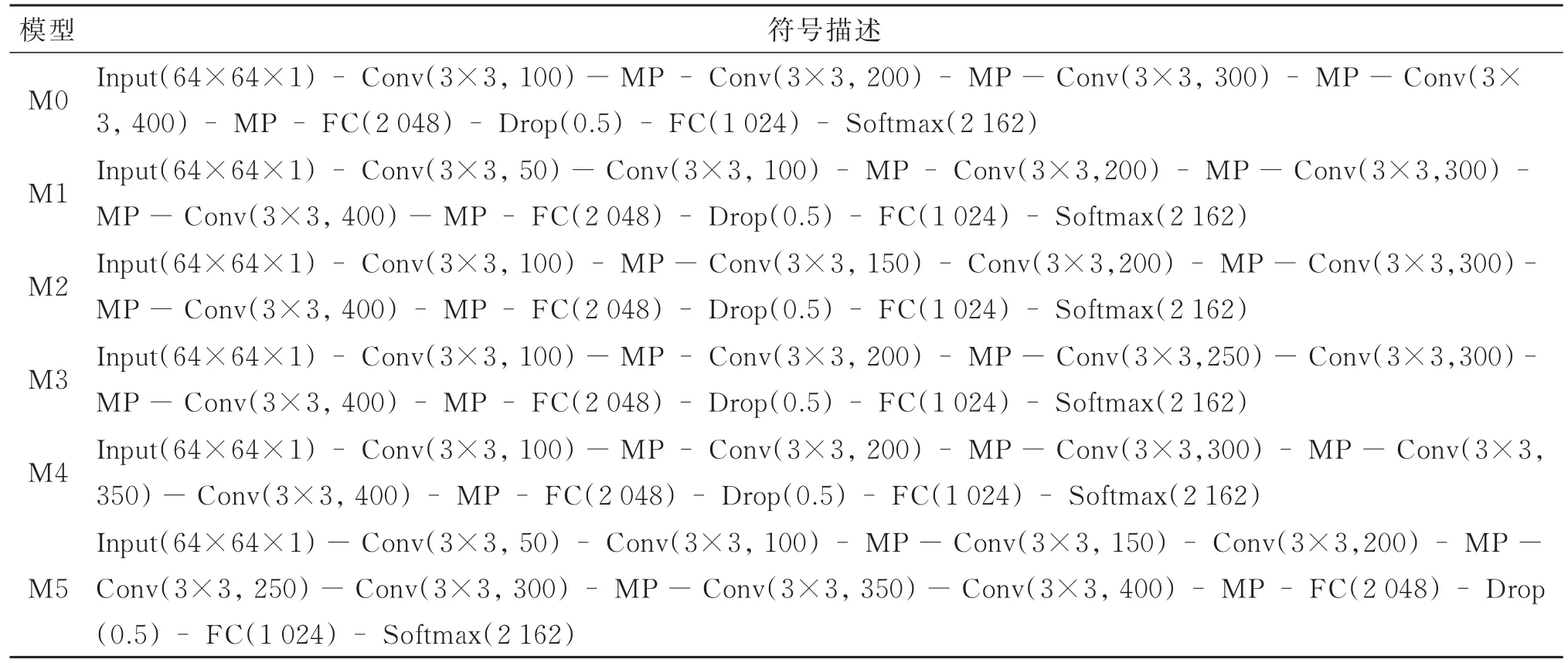
��1 M0��M5���Ż�����Table 1 The symbolic description of M0 to M5

2 Alpha-Betaɢ�ȵ��Ա���ṹ
����CNNģ�͵ı����������������ģ���ͬ��ģ�Ͷ���ͬһ������Ľ������Ҳ������ͬ����Ҫ���Dz�ͬģ�Ͷ��ھֲ����ʶ��Ŀ��Ŷȣ���Ҫ����ģ�Ͷ�������ķ���Ч��[12-13]�����Ĺ�����һ�ַ�����ɢ�ȣ���Alpha-Betaɢ����Ϊ�ͷ����ģ��M0��M5�������Ԫ���½����Ա���[14-15]��֮������2��ȫ���Ӳ��������ѹ�������ʹ��һ��Softmax��Թ������ַ�������������[16]���õ�����ʷֲ���
����P��Q��ͬһ���ռ��е�2�������ܶȺ���������֮���Alpha-Betaɢ�ȿɱ�ʾΪ[15]
���У�α,β,α+β≠ 0��ʽ��1������Լ��������
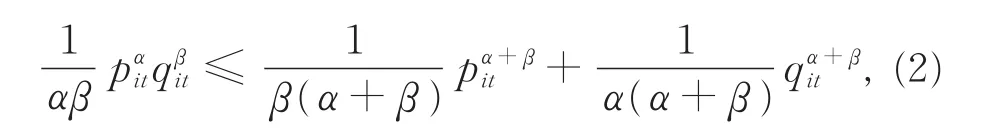
����α,β,α+β≠ 0��
Ϊ������ijһֵ�´��ڲ�ȷ���Ժ������ԣ�Alpha-Betaɢ�ȱ���չ���������е�ʵ����α,β∈R�����Alpha-Beta�ɸ�ֱ�ӵر�ʾΪ
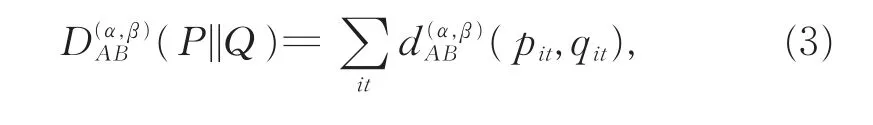
����

���Ķ�M0��M5�������Ԫ��Alpha-Betaɢ��Ϊ�ͷ������½����Ա���ѧϰ����ͼ4��ʾ����ͨ��2��ȫ���ӳ�ȡ��������M0��M5ģ��ȫ���Ż��������Թ�����ʶ��ľ��ȡ�

ͼ4 ����Alpha-Betaɢ���Ա����ں�ģ��M6Fig.4 Based on Alpha-beta divergence self-coding fusion model M6
�����Ա���������ԭ��[17-18]��ѧϰһ��������ʹ��hw,b(x)≈x����xˆ≈x����a(2)j(x)��ʾ�ڸ�������Ϊx������£��Ա�����������������Ԫj�ļ���ȡ���һ����ʹ
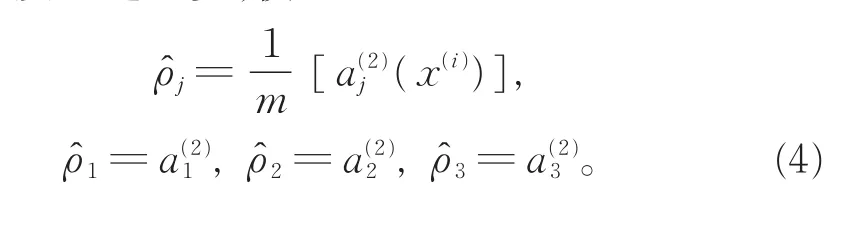
һ��ǿ��Լ��Ϊρˆ→ρ��ρ��һ��ϡ�������ͨ��ȡ�ӽ���0��ֵ����0.05��ÿ�����ص�Ԫj��ƽ������ֵ�ӽ���0.05�����ρˆjΪ���ص�Ԫj��ƽ������ֵ����������һ������ijͷ��������Ż�Ŀ�꺯���� Alpha-Betaɢ��[15]��

��ˣ�ȫ����ʧ����Ϊ
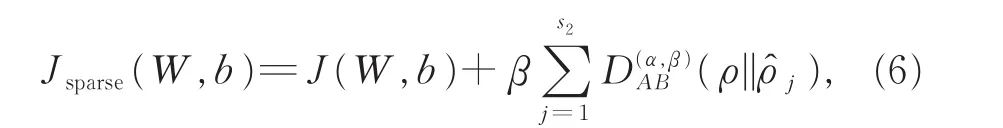
����
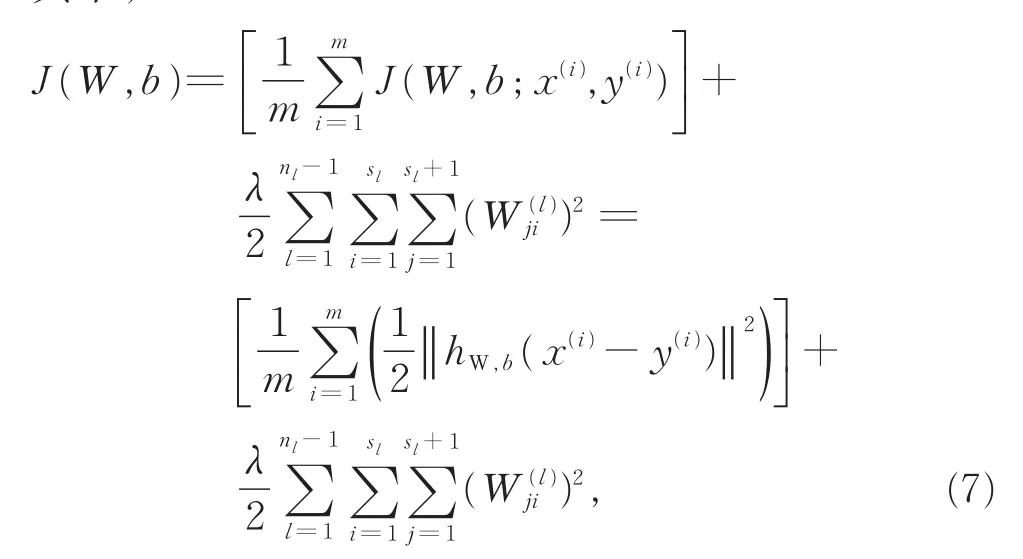
���У�βΪ����ϡ���Գͷ����ӵ�Ȩ�أ�ρˆj����ӵأ�ȡ����W��b������Ϊ��M0��M5Ϊ��������һ���ز���Ԫj��ƽ������ȣ������ز���Ԫ�ļ����ȡ����W��b�����ˣ�����ɶ�M0��M5����Ԫ�����±��롣
3 ģ��ѵ���������ɼ�
3.1 ģ��ѵ��
��ģ�͵ļ��������ΪReLU[19]��ѡ��Adam[20-21]�Ż��㷨��ͬʱ��ѵ������������������������ʹģ���ܸ���ֵ�ѧϰ��ͼ���е����������⣬Ϊʹģ��˳��������Ϊÿһ�����㸽��һ��Batch Norm�㡣
��Ȼ��Adam�㷨����Ч�ʸߡ�ʵ�ַ��㡢�ڴ�ռ���١����²������ݶȴ�С���ʼѧϰ���أ���������������ݼ��ϣ����Ż�Ч�������ԡ���ѧϰ��Ϊ0.001ʱ����ʧ��������������������ѧϰ������Ϊ0.000 1ʱ����ʧ������ʼ�½�����ͼ5��ʾ����˱��Ľ���ʼѧϰ������Ϊ0.000 1��
3.2 �����ɼ�
������Դ��37���ֵġ�������־����������ѡȡ2 142�����ù������ַ�[22]��������������ʦ��ѧ��������ġ��������1 200�ݲɼ�������ͼ6��ʾ����������������ɼ���800�ݡ����ʷ��ɼ���200�ݡ�Ӳ�ʷ��ɼ���200�ݣ���ͼ7��ʾ�����õ���151 200������������ͬʱ��Ϊ���ں��ڴ����������������Ӧ������⣨��ͼ8��ʾ�����������뷨��
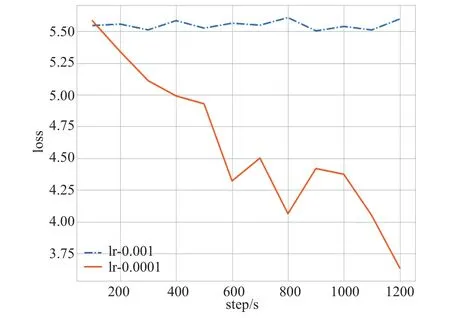
ͼ5 ģ��M0��ͬѧϰ���µ���ʧ����Fig.5 Model M0 loss function under different learning rates

ͼ6 �ɼ���ɨ������Fig.6 The sample of collection table scanned

ͼ7 ������Ӳ�ʣ��ϣ������ʣ��£����Fig.7Hard-tipped ancient Yi��above��and soft-tipped Yi��below��

ͼ8 �����������Fig.8 Ancient Yi font library
Ϊȷ��ģ���ܹ�ѧϰ���㹻�������������������������������������������ͼ9��ʾ�����ȣ���ԭʼ�������п��ȱ仯�͵����α䣬Ȼ������ת�����š�ƽ�Ƶȷ���任����������ģ�����룬��������ȼ��Աȶȱ任�������������ʾ����ͼ10��ʾ��
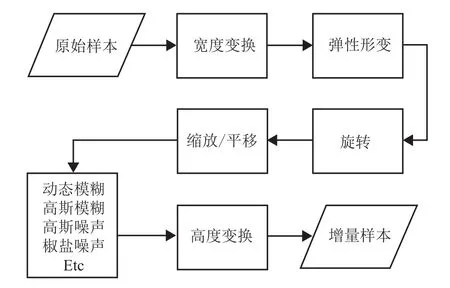
ͼ9 ��������Fig.9 Samples of incremental

ͼ10 �����������Fig.10 The sample after increasing
�������ϴ����õ�ѵ����A��Ϊ�˸���ʵ����֤���ķ�����Ч�����ӹ�����ѧ�о�Ժ�ṩ�ij�����“��ѧ����”֮“����������”Ӱӡ�ļ���ѡȡ��20���ļ���ÿ��Լ150���ַ�����Ϊ�������ݡ����⣬��������������ѵ����A���������������õ�ѵ����A2��
4 ʵ�鼰����
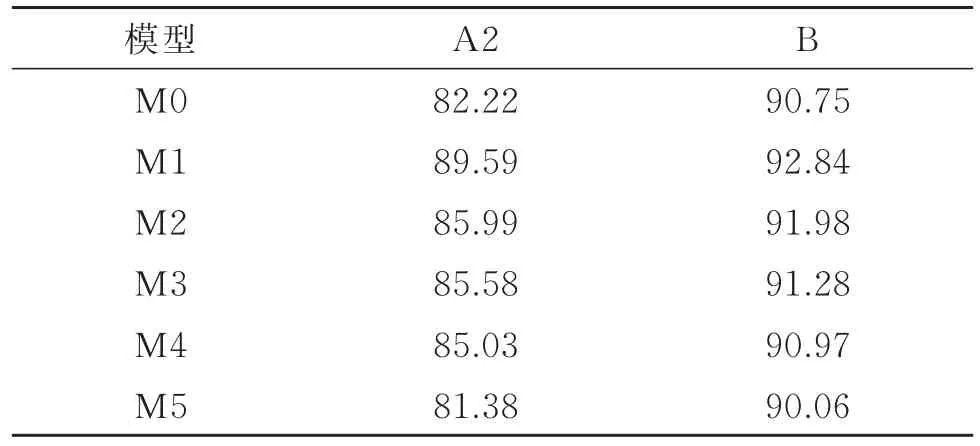
ʹ��ѵ����A2����M0��M5������ѵ�������ڲ��Լ�B�Ͻ��в��ԣ��������2��ʾ��ģ���ڲ��Լ�B�ϵ�ȷ��Զ����ѵ����A2����������ʹ�õ�ģ��ͨ���������ѵ����ѧϰ�����㹻�����д���ͬʱ������������������������ǿ�������Ч�ġ�����һ���棬�ھ����㹻���ѵ��������ѵ������ȷ����δ����90%������������ʹ�õ�ѵ�����ݼ����ܴ���ijЩ����ʶ�����������ѵ�����ݼ������˹��Ų飬��������ԭʼ�����ķֱ��ʹ��ͣ����������εĹ����У����ֲ��������ʼ���ʧ��ճ������ģ�����������ͼ11��ʾ������ͬһ���ַ������ڹ��ȱ��Σ�������ȫƫ���˴��ֵ�������д���������Щ���ȱ��κ������ģ�ʹ���Ķ���������ʹ��ģ����ѵ�����ϱ��ֲ��ѡ�
��2 ģ��M0��M5��ȷ��Table 2 Accuracy of model M0 to M5

ͼ11 ���ȱ��κ������Fig.11 Data after excessive deformation
�ɱ�2��֪��ģ��M1���������ţ����ڲ��Լ�B�ϵ�ȷ�ʴﵽ��92.84%��������ΪM5����Ϊ90.06%����������ģ��M0���������ֱ����Ӷ���ľ����㣬��Ȼ������ģ�����ܵ�������������ģ�Ͳ���λ�õ����Ǩ�ƣ�������������С����ģ��M5��ÿ��������ǰ�������˶���ľ����㣬�����ﵽ���õ�Ч������ʵ���ȴ��ģ�����������½���
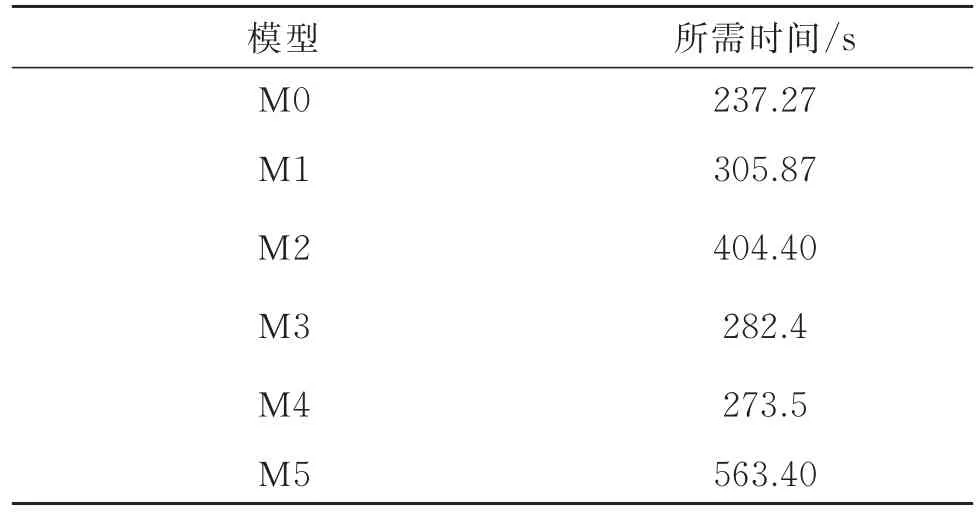
���⣬��4չʾ�˲�ͬģ�͵���100�������ĵ�ʱ�䣬�������ʣ����ģ��M0�����ĵ�ʱ�����٣���Ϊ237.27 s����ģ��M5������ʱ��ߴ�563.40 s��ͬʱ�����Ų��������λ�õ����ߣ�����Ҳ��֮���࣬��Ӧ�أ�����ʱ��Ҳ�������ӡ���M3��M4��M2��ȣ�ȴ����������ʱ����ٵ����������Ҫ���������Ų��������࣬����ͼ�ߴ���С�����������١����3��ʾ����ģ��M0��ȣ�ģ��M2���ӵ�����������࣬�ﵽ��2.07×109����ģ��M3��M4���ӵ�����������ʼ�½�������ģ��M4���ӵ������������٣���Ϊ0.65×109��

��3 ģ��M1��M4��M0������ӵ���������Table 3 The number of connection increasing of M1 to M4 compared to M0
��4 ģ��M0��M5����100�������ĵ�ʱ��Table 4 The time consumed by 100 iterations of the model M0 to M5
�ӱ�2�ͱ�4�п��Կ�����M1�ۺ�������ѣ��ڽ������˼��ټ�������ͬʱ������ȵ������ģ�����ܡ���M5��Ȼ����ò���ʧ��ѡ��ռ���˼���2����M0�ļ���ʱ�䣬���ܲ���������
��һ���������֣��ھ�������ٴν��о�������ȷʵ����������ģ�����ܣ��ҵײ������Ч��Զ���ڸ߲㣬ͬʱ���ײ����ӵĴ���Ҳ��С��������ƫС�����߲����Ӿ���������Ч�������ԣ��һ�����Ӵ�ļ������������˴����IJ���������ģ��M5��ÿ���㶼���Ӿ�������������Ȼ�ڴ��������������ͬʱ��Ҳ�������ݶ���ɢ��
Ϊ���ۺϸ�ģ�͵����ƣ�ʵ�������ͼ3��ģ��M6����ģ��M0��M5��������ʷֲ�Ϊ���룬��ѵ����A2�Ͻ���ѵ�����ڲ��Լ�B�Ͻ��в��ԡ��ڲ��Լ�B�ϵ�ȷ�ʴﵽ��93.97%����ѵ����A2�ϵ�ȷ��Ҳ�ﵽ��90.63%��

ͼ12 ģ��M0��M6�ڲ��Լ�B��ȷ�ʵı仯Fig.12 Changes in accuracy of M0 to M6 in test set B
ʵ���һ��������ģ��ȷ�ʵı仯�����ͼ12Ϊģ��M0��M6�ڲ��Լ���������������ӣ���ȷ�ʵı仯��������ʵ�鷢��ģ�͵���������100��150ʱȷ�������ȶ�������������ȷ�������Ա仯������ͼ12�п������Կ�����ģ��M5�����������ڵ�12������ʱ�Ŵﵽ���ȷ��91.06%��������������ģ�͡�ģ��M0��M1�ڵ�8�����ڴﵽ���ȷ�ʣ��ֱ�Ϊ91.54%��92.84%����ģ��M6���ڵ�7�����ڱ�ﵽ�����ȷ��92.97%��ͬʱ���Կ�����ģ��M0��M1��M2��M6�����ٶȽ�Ϊ�ӽ���ͬʱģ��M6�ӵ�7�����ڿ�ʼ�ʹﵽ���ƽ�ȵ�״̬��������ģ����ﵽƽ��״̬��������ԣ�ģ��M6��������ģ�ͣ�������M6������ģ�͵������Ԫ�������±����Ż��Ľ����
5 �� ��
�������ѧϰ��CNN����Թ��������ݼ�����ʶ�𣬾��нϸߵ�ʶ�ȡ��ر��Dz�����Alpha-Betaɢ����Ϊ�ͷ���Ը���ģ�͵������Ԫ���½����Ա������ɵ��ںϷ������ڼ�����������������£�������ʶ����������ܣ�ͬʱ������������������Ӵ����������½����⡣��ǰ�����ĵ�ʶ���о��д����Σ��Ҵ�������д�淶����д���ӡˢ�壬�����ַ������ޣ������ڶԳ��������Ĵ�������������Ĺż��й�����ʶ�������о��dz�ϡ�٣�����˵�ǵ�ǰ�������о��Ŀհס�
���Ľ����ѧϰ����Ӧ����������������ִ��������Ļ������ͷ�չ����һЩ�����̽�������⣬���ǵ����ĶԸ���ģ��������������Ա�����ںϷ������õ��Ǹ��ʷֲ��Ķ�����ʽ����Ҫ������������������ͬ����д�������ж������۽ϴ�����������ѧϰ�����ɶԿ����磨GANs�����ɸ���Ĺ�������д��������